Discussion¶
Writing macros is not easy, to say the least. Thus, although you could theoretically “do whatever the hell you want” when writing macros, you probably don’t want to. Instead, you should minimize what the macros do, avoid them entirely when not necessary, be concious of the amount of magic you introduce and think hard about what, exactly you want to do with them.
Minimize Macro Magic¶
This may seem counter-intuitive, but just because you have the ability to do AST transformations does not mean you should use it! In fact, you probably should do as little as is humanely possible in order to hand over control to traditional functions and objects, who can then take over.
For example, let us look at the Parser Combinators macro, shown in the examples above. You may look at the syntax:
value = '[0-9]+'.r // int | ('(', expr, ')') // f[_[1]]
op = '+' | '-' | '*' | '/'
expr = (value is first, (op, value).rep is rest) >> reduce_chain([first] + rest)
And think this may be an ideal situation to go all-out, just handle
the whole thing using AST transforms and do some code-generation to
create a working parser! It turns out, the peg module does none of
this. It has about 30 lines of code which does a very shallow
transform from the above code into:
value = Named(lambda: Raw('[0-9]+').r // int | Seq(Raw('('), expr, Raw(')')) // (lambda x: x[1]), "value")
op = Named(lambda: Raw('+') | Raw('-') | Raw('*') | Raw('/'), "op")
expr = Named(lambda: Seq(Named(lambda: value, "first"), Named(Seq(op, value).rep, "rest")) >> (lambda first, rest: reduce_chain([first] + rest)), "expr")
That’s the extent of the macro! It just wraps the raw strings in
Raw, tuples in Seq instances, converts the a is b syntax
into a.bind_to("b") and wraps each assignement in a named, lazy
parser to facilitate error reporting and to allow circular references
between them. The rest, all the operators | // >>, the
.r syntax for regexes and .rep syntax for repetitions, that’s
all just implemented on the Raw objects using plain-old operator
overloading and properties.
Why do this, instead of simply implementing the behavior of |
// and friends as macros? There are a few reasons
- maintainability: tree transforms are messy, methods and
operators are pretty simple. If you want to change what
.rdoes, for example, you’ll have a much easier time if it’s a@propertyrather than some macro-defined transform; - consistency: methods already have a great deal of pre-defined semantics built in: how the arguments are evaluated (eagerly, left to right, by-value), whether they can be assigned to or monkey-patched. All this behavior is what people already come to expect when programming in Python. By greatly limiting the macro transforms, you leave the rest up to the Python language which will behave as people expect.
It’s not just the Parser Combinators which work like this; PINQ to SQLAlchemy, Tracing, Pattern Matching all work like this, doing the minimal viable transform and delegating the functionality to objects and functions as soon as possible.
No Macros Necessary¶
Python is a remarkably dynamic language. Not only that, but it is also a relatively large language, containing many things already built in. A large amount of feedback has been received from the online community, and among it suggestions to use macros for things such as:
- before and After function advice: code snippets to hook into the function call process;
- Auto parallelizing functions, which run in a forked process
This stackoverflow question also explores the use cases of Macros in Python, and comes up with a large number of unimaginative suggestions:
- An
unless blah:statement, equivalent to anif not blah: - A
repeatmacro, to replace for-loops - A
do whileloop
The last three examples are completely banal: they really don’t add anything, don’t make anything easier, and add a lot of indirection to no real gain. The first two suggestions, on the other hand, sound impressive, but are actually entirely implementable without Macros.
Function Advice¶
Function advice, part of AOP, is a technique of register code snippets to run before or after function calls occur. These could be used for debugging (printing whenever a function is run), caching (intercepting the arguments and returning the value from a cache if it already exists), authentication (checking permissions before the function runs) and a host of other use cases.
Although in the Java world, such a technique requires high-sorcery with AspectJ and other tools, in Python these are as simple as defining a decorator. For example, here is a decorator that logs invocations and returns of a generic python function:
def trace(func):
def new_func(*args, **kwargs):
print("Calling", func.func_name, "with", args, kwargs)
result = func(*args, **kwargs)
print("func.func_name, "returned", result)
return result
return new_func
@trace
my_func(arg0, arg1):
... do stuff ...
Similar things could be done for the other use cases mentioned. This
is not a complete example (it would need a functools.wraps or
similar to preserve the argspec etc.) but the point is that
writing such a decorator really is not very difficult. No macros
necessary!
Auto-Parallelization¶
Another suggestion was to make a decorator macro that ships the code
within the function into a separate process to execute. While this
sounds pretty extreme, it really is not that difficult, for in Python
you can easily introspect a function object and retrieve it’s code
attribute. This can pretty easily be pickled and sent to a child
process to be executed there. Perhaps you may want some sort of
Future container to hold the result, or some nice helpers for
fork-join style code, but these are all just normal python functions:
no macros necessary!
Thus, you can accomplish a lot of things in Python without using
macros. If you need to pass functions around, you can do so without
macros. Similarly, if you want to introspect a function and see how
many arguments it takes, you can go ahead using
inspect. getattr, hasattr and friends are sufficient for
all sorts of reflective metaprogramming, dynamically setting and
getting attributes. Beyond that, you have the abilities to access the
locals an globals dictionaries, reflecting on the call stack
via inspect.stack() and eval or execing source
code. Whether this is a good idea is another question.
Levels of Magic¶
MacroPy is an extreme measure; there is no doubting that. Intercepting the raw source code as it is being imported, parsing it and performing AST transforms just before loading it is not something to be taken lightly! However, macros are not the most extreme thing that you can do! If you look at an Magic Scale for the various things you can do in Python, it may look something like this:
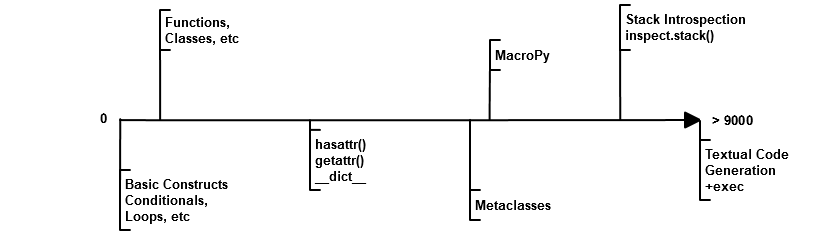
Where basic language constructs are at 0 in the scale of magic,
functions and classes can be mildly confusing. hasattr and
getattr are at another level, letting you treat things objects as
dictionaries and do all sorts of incredibly dynamic things.
I would place MacroPy about on par with Metaclasses in terms of their
magic-level: pretty knotty, but still ok. Past that, you are in the
realm of stack.inspect(), where your function call can look at
what files are in the call stack and do different things depending
on what it sees! And finally, at the Beyond 9000 level of magic,
is the act of piecing together code via string-interpolation or
concatenation and just calling eval or exec on the whole blob,
maybe at import time, maybe at run-time.
Skeletons in the Closet¶
Many profess to shun the higher levels of magic “I would never do
textual code generation!” you hear them say. “I will do things the
simple, Pythonic way, with minimal magic!”. But if you dig a little
deeper, and see the code they use on a regular basis, you may notice
some namedtuple in their code base. Looking up the implementation
of namedtuple
brings up this:
template = '''class %(typename)s(tuple):
'%(typename)s(%(argtxt)s)' \n
__slots__ = () \n
_fields = %(field_names)r \n
def __new__(_cls, %(argtxt)s):
'Create new instance of %(typename)s(%(argtxt)s)'
return _tuple.__new__(_cls, (%(argtxt)s)) \n
@classmethod
def _make(cls, iterable, new=tuple.__new__, len=len):
Runtime code-generation as strings! It turns out they piece together
the class declaration textually and then just exec the whole
lot. Similar things take place in the new Enum that’s going to enter
the standard library. Case Classes may be magical,
but are they really any worse than the status quo?
Beyond Python, you have the widely used .NET’s T4 Text Templates and Ruby on Rails code-generation tools. This demonstrates that in any language, there will be situations where dynamic generation/compilation/execution of source code begin to look attractive, or even necessary. In these situations, syntactic macros provide a safer, easier to use and more maintainable alternative to this kind of string-trickery.
Whither MacroPy¶
When, then, do you need macros? We believe that the macros shown above are a compelling set of functionality that would be impossible without macros. The things that macros do roughly falls into the following categories:
Boilerplate Shaving¶
Parser Combinators, Quick Lambdas and Case Classes are examples of boilerplate shaving, where macros are used to reduce the amount of boilerplate necessary to perform some logic below the level that can be achieved by traditional means of abstraction (methods, operator overloading, etc.). With the Parser Combinators, for example, the macro transform that is performed is extremely simple and superficial. This is also the case with the other boilerplate shaving macros.
In these macros, the boilerplate that the macro removes is trivial but extremely important. Looking again at the Parser Combinator transformation, it is clear that removing the boilerplate is a huge improvement: rather than having to dig through the code to figure out what happens, the PEG-like structure of the code jumps right out at you making it far easier to see, at a glance, what is going on.
Source Reflection¶
Source reflection is the use of macros to take the source code of the program and making it available for inspection at run-time. For example, if we re-examine the error-reporting example from MacroPEG:
json_exp.parse('{"omg": "123", "wtf": , "bbq": "789"}')
# ParseError: index: 22, line: 1, col: 23
# json_exp / obj / pair / json_exp
# {"omg": "123", "wtf": , "bbq": "789"}
# ^
# expected: (obj | array | string | true | false | null | number)
We can see that MacroPEG is able to place the names of each parser in
the ParseError’s error message. This of course is very handy when
debugging your parsers, as well as being useful in debugging malformed
input.
One question that you may ask is, how is MacroPEG able to access the names of each parser, given that the name of each parser is only provided in its variable name? Recall that MacroPEG parsers are defined as follows:
with peg:
json_exp = (space, (obj | array | string | true | false | null | number), space) // f[_[1]]
obj = ...
array = ...
string = ...
...
The answer is that MacroPEG captures the variable-name of each parser and passes it to the parser’s constructor, performing a transform similar to:
obj = ... -> obj = Named(..., "obj")
By doing this, now you are able to get sensible error messages when using your parsers, without having to manually label each parser with a name in addition to the variable to which it’s assigned.
Apart from MacroPEG, the Tracing macros also operates on the same principle, capturing the source code of each snippet as a string that is passed to the code at run-time for printing. This is something which is impossible to do using normal Python code, and the only answer is the repetitive definition of each variable, statement or expression together with its string representation, a task which is extremely tedious to perform by hand.
Mobile Code¶
Macros such as PINQ to SQLAlchemy, JS Snippets, Tracing and potential extensions such as the Fork-Join macros are all about using macros to shuttle code between domains, while still allowing it to be written together in a single code base. PINQ and JS Snippets are all about taking sections of a Python program and executing it either on a remote database or in a browser, while the Tracing macro ships sections of code into the console for debugging purposes and the Fork-Join macro would shuttle sections of code between Python processes in order to run them in parallel.
This idea of mobile code is not commonly seen in most domains; more often, code written in a single file is run in a single place, and if you want to write a distributed system, you’ll need to manually break up your code even though conceptually it all belongs together. Allowing you to have a single code-base and semi-transparently (translucently?) ship the code to somewhere else to run would be a big step forward.
Note how none of these macros are simple things like do-while loops or alternate syntaxes for if-else statements; these categories of macros perform useful functions, often completely impossible without macros, and have to be carefully crafted so as to minimize the confusion caused by the macro transformation.